MLLME-NER: Named Entity Recognition via Efficient Multi-LLM Ensemble Learning
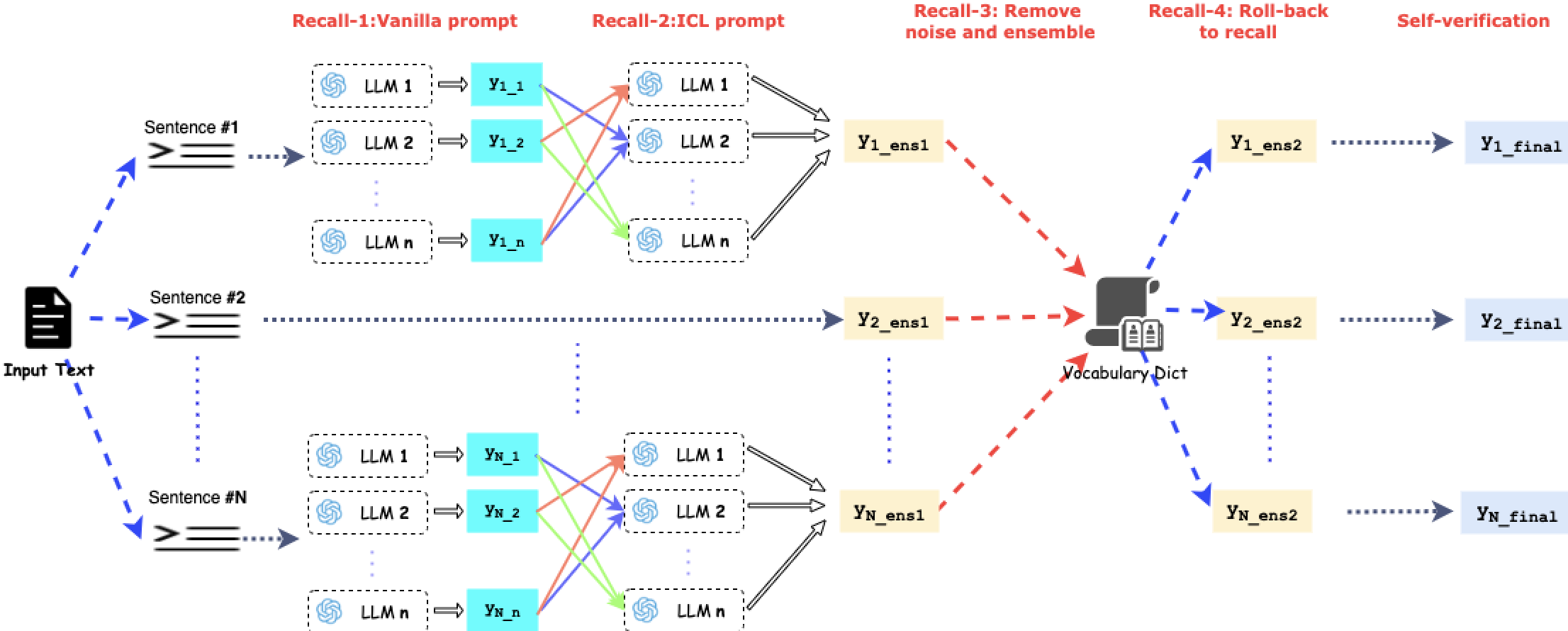
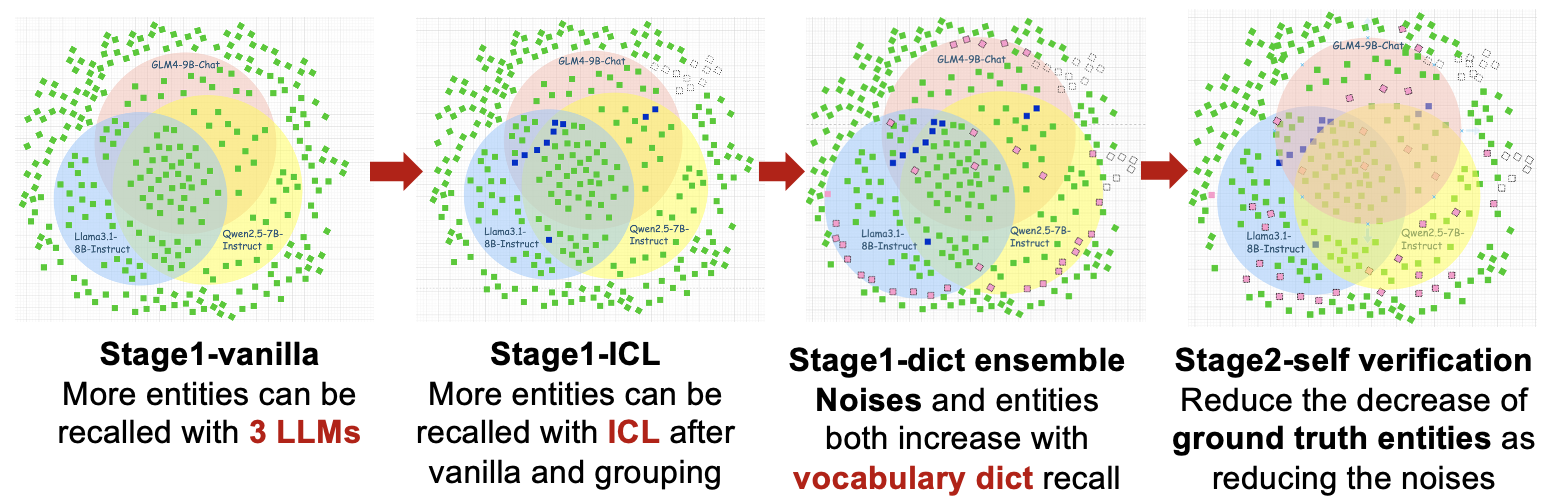



Recently, Large Language Models (LLMs) have shown remarkable performance on NER tasks due to its excellent capability of generalization and language understanding. However, real-world texts encounter challenges such as multi-source, lack of labeling, fine-grained recognition, which is a low-resource situation and different from experimental scenarios. These problems limits the training of traditional NER models and the fine-tuning of LLMs, where zero-shot reasoning ability makes LLMs handle them feasibly through prompting engineering. Current NER work with LLMs typically rely on a single LLM, while open-source LLMs exhibit diverse strengths and weaknesses due to variations in data, architectures, and hyper-parameters, making them complementary to each other. Therefore, we propose MLLME-NER, an ensemble learning framework designed to utilize the strengths of each LLM and eliminate the weaknesses caused by training corpus, architectures and so on. This framework consists of two following stages. Stage 1: Recall-Oriented stage. In this stage, we use multiple LLMs to self-annotate unlabeled texts separately and use the above results to re-annotate with In Context Learning (ICL) prompting skills. Besides, we build a vocabulary dict with re-annotated results after removing noise and use this dict to recheck each sentence. Stage 2: Precision-Oriented stage. We use LLM which has largest parameters to self-verify result of each sentence to improve precision.